Understanding Vector Databases¶
In mathematics and physics, a vector is a term that refers colloquially to quantities. Usually those quantities can't be expressed by a single number (a scalar). Imagine an arrow connecting an initial point A with a terminal point B. This arrow represents a vector, and it’s what you need to “carry” point A to point B. In simple words, a vector is like an arrow. You can use the arrow to learn where things are in a space, and the arrow shows both the distance and the direction.
A vector space is a set of vectors that can be played with each other. You can add or multiply them, but need to follow some certain rules.
What is a vector's dimension?¶
To better describe a ‘vector’, we need to understand what does dimension mean. A dimension is a way to describe how many directions something can be measured. In physics and mathematics, the dimension of a mathematical space (or object) is informally defined as the minimum number of coordinates needed to specify any point within it. A line has a dimension of one (1D) because only one coordinate is needed to specify a point on it – for example, the point at 5 on a number line. A surface, such as the boundary of a cylinder or sphere, has a dimension of two (2D). Because two coordinates are needed to specify a point on the surface. For example, both a latitude and longitude are required to locate a point on the surface of a sphere. In a cube, a cylinder or a sphere is three-dimensional (3D). Because three coordinates are needed to locate a point within these spaces.
What is a high-dimensional vector?¶
A high-dimensional vector is like a long arrow. The arrow points in many different directions at once (hard to imagine). Each direction represents a different feature or aspect of something.
Let's say we have a vector that represents a picture of a dog. In a low-dimensional vector, we might only have a few directions representing basic features like color and type. But in a high-dimensional vector, we could have hundreds or even thousands of directions. Those directions represent features. Like the shape of the dog ears, the color of the eye, the texture of its fur and so on.
So, a high-dimensional vector is like a detailed description of something. The description contains different aspects or features and was packed into one long arrow (a heavy arrow as well). These high-dimensional vectors are used in things like machine learning and data analysis to capture complex information of something and relationships between things.
What is embedding?¶
In natural language processing, words are represented as vectors in a high-dimensional space, where each dimension of the space corresponds to a specific aspect or feature of the word's meaning. For example, dimensions might represent things like context, semantics, or syntax.
The procedure to generate the vectors from words is called embeddings. Embeddings capture semantic relationships between words or documents by mapping them to continuous vector representations. In such a way, similar words or documents are closer together in the vector space.
Introduction to vector search¶
Co-location of similar words¶
In the vector space, the co-location of similar words refers to the phenomenon: words with similar meanings or semantic relationships are represented by vectors that are close to each other. This means that in the vector space, words are represented as high dimensional vectors. Similar words tend to have vectors that are positioned nearby.
Let's consider a simplified two-dimensional vector space where words are represented by points. In this space, for example, the word "joy" is represented by point (2, 3). The word "happy" is represented by the point (3, 4). Since they're similar in meaning, their vectors are positioned close to each other in the vector space. The word “sad” is represented by point (-5, -8), as it has an opposite meaning of joy, and their vectors are positioned far from each other.
The co-location of similar words in the vector space is crucial for various natural language processing tasks. Machine learning models use the information to capture and understand the semantic relationships between words. This information can be used in sentiment analysis, contextual information, language translation, and more.
A query will also be ‘translated’ into high dimensional vectors and find a match in the vector space. It's possible to get the results in different media format or even languages than the query content itself.
How vector search works¶
In vector query execution, the search engine looks for similar vectors to find the best candidates to return in search results. Depending on how you indexed the vector content, the search for relevant matches is either exhaustive, or constrained to near neighbors for faster processing. Once candidates are found, the results are scored using similarity metrics based on the strength of the match.
There are some popular algorithms used in vector search:
"KNN"(K-Nearest Neighbors): is a commonly used classification and regression algorithm. Suppose a classification task receives a training dataset and a new input instance. The task finds the K instances in the training dataset that are closest to the instance. If most of these K instances belong to a certain class, then the input instance is classified as this class.
"ANN"(Approximate Nearest Neighbors): is an algorithm for finding approximate nearest neighbors in large datasets. Unlike the KNN algorithm, which finds the exact nearest neighbors, the ANN algorithm only finds approximate nearest neighbors.
Both KNN and ANN are algorithms based on distance measurements to find the nearest neighbors. KNN finds the exact nearest neighbors, while ANN finds the approximate nearest neighbors. ANN can significantly improve search efficiency then KNN when dealing with massive data, especially in high-dimensional space searches.
"HNSW" (Hierarchical Navigable Small World): During indexing, HNSW creates extra data structures for faster search, organizing data points into a hierarchical graph structure. HNSW has several configuration parameters that can be tuned to achieve the objectives for your search application. Like throughput, latency, and recall. For example, at query time, you can specify options for exhaustive search, even if the vector field is indexed for HNSW.
During query execution, HNSW enables fast neighbor queries by navigating through the graph. This approach strikes a balance between search accuracy and computational efficiency. HNSW is recommended for most scenarios because of its efficiency when searching over larger data sets. In some vector databases, HNSW (Hierarchical Navigable Small World) does an Approximate Nearest Neighbor (ANN) search. Such as Azure AI Search.
How does index help improve the vector search efficiency¶
An index is a data structure that improves the speed of data retrieval operations on a database table. It works by creating a copy of a subset of the data. The copy allows the database to find the location of the desired rows in the table more quickly. Using an index in vector search has several benefits: It reduces the number of vectors that need to be compared to the query vector. The query is more efficient. Also it greatly reduces memory requirements and enhances accessibility when contrasted with processing searches via raw embeddings
A couple of popular indexing methods:
"Flat" index refers to a type of index structure that stores vectors in a flat, unstructured format. Flat index doesn't have any precomputed structures, which means each query needs to go through every single vector in the database to find its nearest neighbors. Tree-based or hierarchical indexes, are faster in searching but sacrifice accuracy. Flat indexes are typically used as a baseline to evaluate the performance of more complex index structures.
“IVF” stands for Inverted File. It's a type of indexing method frequently used in large-scale vector search and retrieval. In an IVF system, the dataset is first partitioned into several clusters. For each cluster, an inverted file (a list) is created that keeps track of the vectors that belong to this cluster. The advantage is during a search, you only need to search within the relevant clusters instead of the entire dataset. IVF index can significantly reduce the computational cost and improve search efficiency.
IVF is often combined with other techniques such as Product Quantization (PQ) to further improve search performance, especially in high-dimensional spaces.
"VPT" stands for Vantage-Point Tree. It's an index structure for performing efficient nearest neighbor search in a metric space. The Vantage-Point Tree is built by selecting a vantage point and partitioning the data into two parts: points that are nearer to the vantage point than a threshold, and points are not. This process is then recursively applied to both parts.
When doing a search, the VPT excludes large portions of the data from consideration, making the search process faster than a simple linear search. It's effective in low-dimensional spaces. However in high-dimensional spaces, the VPT can suffer from the curse of dimensionality, which makes it less efficient than other methods like KD-trees or Ball trees.
Introduction to hybrid search¶
Why use hybrid search¶
Hybrid query is a combination of full text or keyword search that contains both searchable plain text content and generated embeddings. For query purposes, hybrid search is:
- A single query request that includes both search and vectors query parameters
- Executing in parallel
- With merged results in the query response, scored using Reciprocal Rank Fusion (RRF)
Hybrid query combines the strengths of vector search and keyword search. The advantage of vector search is finding information that's conceptually similar to your search query, even if there are no keyword matches in the inverted index. The advantage of keyword or full-text search is precision, with the ability to apply semantic ranking that improves the quality of the initial results. Some scenarios - such as querying over product codes, highly specialized jargon, dates, and people's names - can do better with keyword search because it can identify exact matches.
Benchmark testing on real-world and benchmark datasets indicates that hybrid retrieval with semantic ranking offers significant benefits in search relevance.
Reciprocal Rank Fusion (RRF)¶
Reciprocal Rank Fusion (RRF) is an algorithm that evaluates the search scores from multiple, previously ranked results to produce a unified result set. RRF is based on the concept of reciprocal rank, which is the inverse of the rank of the first relevant document in a list of search results. The goal of the technique is to take into account the position of the items in the original rankings, and give higher importance to items that are ranked higher in multiple lists. RRF can help improve the overall quality and reliability of the final ranking, making it more useful for the task of fusing multiple ordered search results.
Vector database VS traditional database¶
A vector database is a type of database that is designed to store, manage, and index massive quantities of high-dimensional vector data efficiently. In traditional relational databases, data points are represented with rows and columns. In vector database, data points are represented by vectors with a fixed number of dimensions, clustered based on similarity.
Vector databases are important in different fields. Vector databases can efficiently store, organize, and search high-dimensional data points (also called vectors). These databases handle data where each entry is like a point in a multi-dimensional space. These vector databases are crucial for tasks like machine learning and natural language processing. Think of them as special tools that help computers find similar things. Vector databases offer an intuitive way to find similar objects, answer complex questions, and understand the hidden context of complex data.
Large language models (LLMs) have enabled many new and exciting applications to be built. But a known shortcoming of LLMs is that a trained language model doesn't have knowledge of recent events, or knowledge available only in proprietary documents. Because the model did not get to train on such knowledge. To tackle this problem, you can use retrieval augmented generation or RAG. And a key component of RAG is a vector database.
Proprietary or recent data is first stored in this vector database. Then, when there's a query that concerns that information, that query is sent to the vector database, which then retrieves the related text data. And finally, this retrieved text can be included in the prompt to the LLM to give it context with which to answer your question. Vector databases preceded this recent generative AI explosion. But vector databases have long been a broad part of semantic search applications. These applications search on the meaning of words or phrases rather than keyword search that looks for exact matches. In recommender systems, vector databases have been used to find related items to recommend to a user.
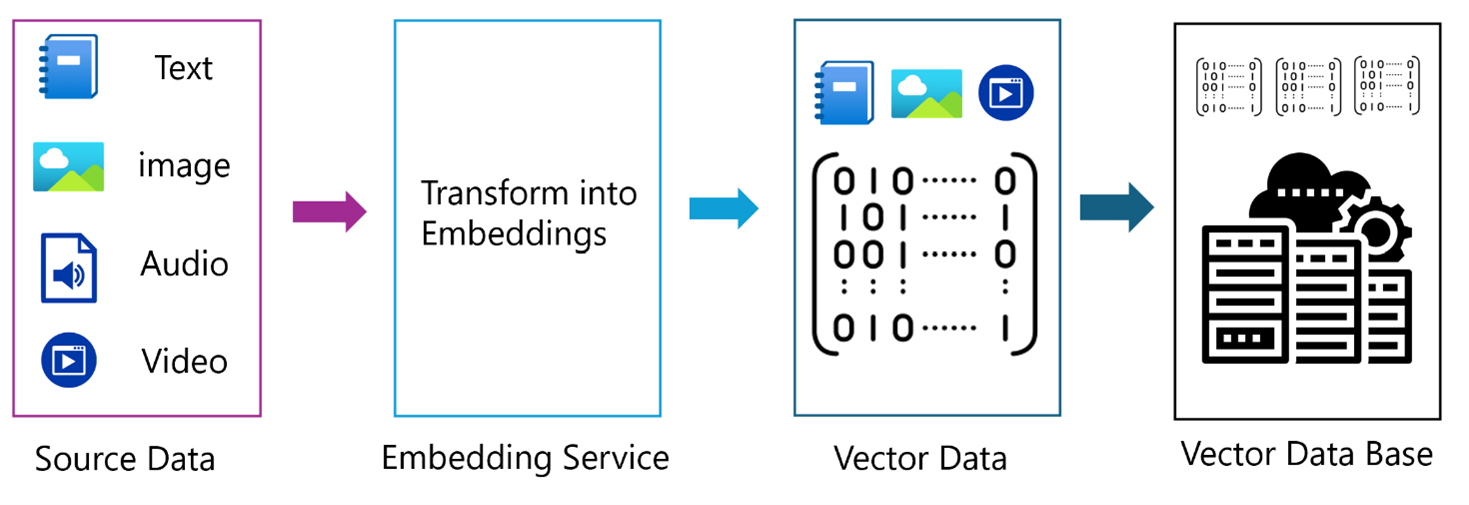
This process diagram depicts the transformation of various file formats, including text, images, audio, and video, into vector representations via an Embedding Service. Later, these vectors are stored in a Vector Database for efficient management and accessibility.
To learn more about RAG and vector indexing, refer to the documentation:
Traditional databases, organize data into tables, rows, and columns. They use Structured Query Language (SQL) to manage and manipulate the stored data. They're good at handling structured data, with well-defined schemas that facilitate data organization and querying.
The choice between a vector database and a traditional database should be informed by a couple of factors: your specific use case, data types, performance requirements, and scalability needs. Vector databases are great for finding similar things and helping with machine learning. On the other hand, traditional databases are better at handling structured data and making sure transactions go smoothly.
What’s covered in this playbook¶
The playbook contains collection of samples that demonstrates how to use different vector database tools in Azure to store embeddings and construct complex queries from text, documents and images. Each sample contains IaC scripts to spin up vector storage on Azure.
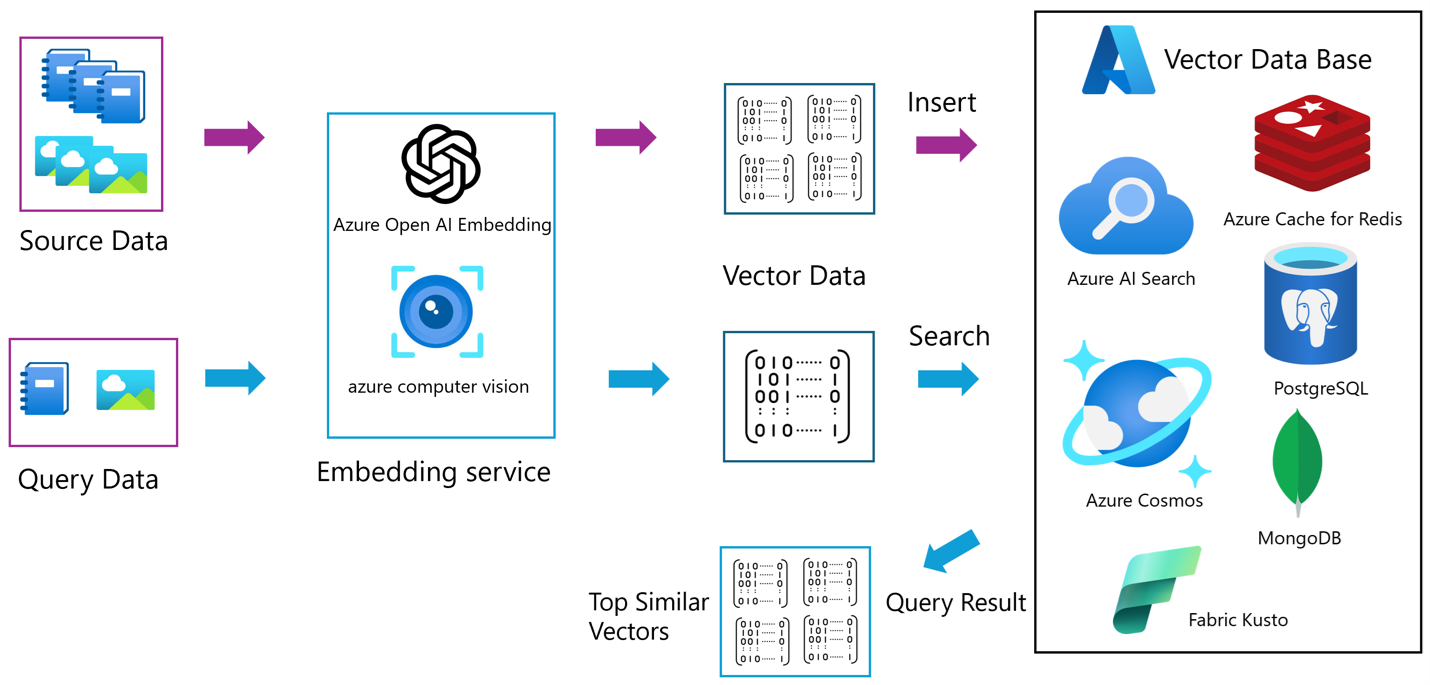 This flow chart outlines the process that is implemented by the sample code, where source data and query data are processed by Azure Open AI and Azure computer vision Embedding to produce vector data. The vector data is then inserted into a vector database, such as Azure Cache for Redis, Azure AI Search, PostgreSQL, Azure Cosmos, and MongoDB. A search operation within this database identifies the top similar vectors, leading to the final query result.
This flow chart outlines the process that is implemented by the sample code, where source data and query data are processed by Azure Open AI and Azure computer vision Embedding to produce vector data. The vector data is then inserted into a vector database, such as Azure Cache for Redis, Azure AI Search, PostgreSQL, Azure Cosmos, and MongoDB. A search operation within this database identifies the top similar vectors, leading to the final query result.
The services are commonly used in all samples of the playbook.
- Azure OpenAI Embedding Service: An embedding is a special format of data representation that can be easily used by machine learning models and algorithms. The embedding is an information dense representation of the semantic meaning of a piece of text.
- Azure Computer Vision Multi-modal embeddings: Multi-modal embedding is the process of generating a numerical representation of an image that captures its features and characteristics in a vector format. These vectors encode the content and context of an image in a way that is compatible with text search over the same vector space.
Our playbook includes a collection of samples that showcase the using of various vector database tools on Azure. These tools empower us to store vector embeddings and construct intricate queries from diverse data types, including text, documents, and images. Here are the key components of our work:
- Azure AI Search: By augmenting our data with semantic and vector search features, we enhance retrieval-augmented generation (RAG) using large language models (LLMs).
- Azure Database for PostgreSQL: In this context, we store both application data and vector embeddings within a scalable PostgreSQL offering. The native support for vector search enables efficient querying.
- Azure Cache for Redis: While Redis is commonly known for caching, we use it to manage vector embeddings efficiently. Its in-memory data structure store allows for rapid retrieval and manipulation of vectors.
- Azure CosmosDb for PostgreSQL: Our exploration extends to Cosmos DB, where we seamlessly integrate data and vectors. The native vector search capabilities enhance our ability to extract meaningful insights.
- Azure Cosmos DB for MongoDB vCore: This MongoDB-compatible service enables us to store application data and vector embeddings together. With native support for vector search, we achieve efficient retrieval and analysis.
- Fabric Real-Time Analytics (Kusto): This folder includes the notebooks to demonstrate vector search capabilities of Fabric Real-Time Analytics(Kusto) for text, documents and images.
We’ve developed Infrastructure as Code (IaC) scripts to create vector storage on Azure. These scripts streamline the setup process, ensuring consistency and scalability across our vector databases.
Further reading¶
To further learn more about building LLM apps, refer to the links: