Graph database best practices¶
Graph databases are one of the NoSQL options for storing data. While the concept can be easy to understand, the implementation can get complicated. Engineers and architects usually know what nodes and edges are. However, it's not always easy to know when to use a graph database to meet business needs. This article offers some best practices for graph databases in general and Cosmos DB Gremlin API in particular. To improve the success of graph database implementations, use the following tips, specifically when using traversal-based queries to offer a distinct approach to accessing data.
Database agnostic best practices¶
Apply the following guidance for all database implementations regardless of the database technology.
Establish graph use case validity¶
One of the most important best practices, if not the most important, for using graph databases is establishing there's a valid use case for this type of database. And this includes an understanding of costs and benefits trade off for graph databases.
The risks associated with a graph database against its potential value must be considered. If the goal is to ship to production, recommendation is to begin with a relational database and assess where a graph might add value.
Using a graph database beyond a proof of concept can be risky for many reasons:
- Often the query languages are complex and unfamiliar.
- Your team might not have the devops or infrastructure experience to support a graph database in production.
- Adding another data engine to a stack increases complexity and infrastructure overhead.
- Poorly designed graph data access patterns can be costly for cloud computing resources.
For more information, see Design Hybrid Data Architecture.
After attempting to solve the business problem with a relational database, establish whether any of the following problems are present:
- Unwieldy queries due to high cardinality of data.
- The data model is interconnected with complex relationships.
- The schema or DDL changes often to handle evolving relationships.
- The query logic implements repeated cyclic joins with complex conditionals.
- The data access patterns return result set unions with different object types.
When these issues impact data access, it is sometimes beneficial to take the risk of adding a graph database to the data architecture.
In some cases, a graph database might be an anti-pattern. The following issues in a graph implementation might indicate the need to reconsider a relational database instead:
- The data model never changes or changes infrequently.
- Traversals are simple enough to express cleanly as CTEs in SQL.
- Data access patterns are more property focused than path focused.
- Traversals all follow the same edges (low data cardinality).
- Queries consistently return the same node/object types.
Avoid large traversals¶
Often, engineers new to graph databases misuse traversal data access patterns in costly ways. It's not always clear to developers new to graph data engines why you need traversal data access patterns for the use case.
A common pitfall is to query large traversals. Traversals that span super-nodes, or highly interconnected vertices, result in subgraphs that are costly in resource usage and often lack business value.
It's important to remember that the Apache TinkerPop framework offers both analytic and transactional processing. The underlying Gremlin API is transactional. Similarly, SQL Server is a transactional engine and the SQL Graph plugin is limited to the same processing. Analytic queries need to go through lots of data to find important information, and they usually return a smaller set of useful results. It's important to remember that the Apache TinkerPop framework offers both analytic and transactional processing. The underlying Gremlin API is transactional. Similarly, SQL Server is a transactional engine and the SQL Graph plugin is limited to the same processing. Analytic queries need to go through lots of data to find important information, and they usually return a smaller set of useful results.
Supply chain example¶
A concrete example in the supply chain use case for the retail industry is to identify supplier risk. Retailers face supply chain disruptions and need to find and replace suppliers with supply chain risks. If a retailer's analytics team obtains and analyzes data for all industry supplier relationships, what database type will solve this issue?
Suppose the retailer chooses a transactional graph and assigns risk calculations to each supplier in the industry. Direct suppliers of the retailer could be aggregated by risk, based on their 2nd and 3rd tier relationships. While it looks like this is usable for a graph, this method might result in large and costly traversals aggregating risk beyond two or three hops.
A non-graph data store is the better choice for aggregations. If you're using the Cosmos DB Gremlin API, switch to the columnar Cassandra API or the SQL API with Azure Synapse Link for risk aggregations. After identifying risky suppliers, the analytics team loads the data into a transactional graph engine to search for substitute suppliers by querying edge or node properties and ordering them by risk.
The critical takeaway is be sure you know which data engines tools are suitable for which use cases. A transactional system shouldn't be used for an analytic use case, and the other way around.
Avoid relational "lift and shift"¶
One of the best ways to extract value from a graph is to use data modeling to your advantage. As most implementations of graph databases are schemaless, there's minimal risk to trying experimental data modeling designs.
A common anti-pattern is to project the exact data model of a relational database into a graph. Approaching the data thinking about tables as entities and joins as relationships potentially misses the value of attributes describing the relationships.
Understanding the core access patterns and how the business will be querying the relationships determines the best way to model them in a graph database.
Creatively using the following two patterns helps identify how to port tables and foreign keys into nodes and edges more valuably:
- Use joins to aggregate data into node properties
Consider the following example with:
`users` | column | type | |-----------|--------------| | user_id | uuid | | user_name | varchar(255) | `user_groups` | column | type | foreign key | |-----------------|--------------|---------------| | user_group_id | uuid | | | user_id | uuid | users.user_id | | user_group_name | varchar(255) | |One common way to organize the data in a graph data model is by creating
usernodes anduser_groupnodes. This approach might be useful for queries that ask to find connections between users in different groups.However, if the only traversal pattern is to understand which groups users are in, then adding a
user_groupsproperty on theusernodes will suffice. A set of group names or IDs will be easy to retrieve for any given user node. Likely, analysis of this data will make use of both types of data access patterns.
- Explode columns-related tables into more atomic relationships
Consider the following example with vague and abstract tables:
`entities` | column | type | |-------------|--------------| | entity_id | uuid | | entity_name | varchar(255) | | entity_type | varchar(255) | `entity_relationships` | column | type | foreign key | |-------------------|--------------|--------------------| | relationship_id | uuid | | parent_entity_id | uuid | entities.entity_id | | child_entity_id | uuid | entities.entity_id | | relationship_type | varchar(255) |Storing data in a large columnar data store might be helpful, but porting it into a graph would result in a rather trivial graph with one node and one edge type.
Using
entity_typeandrelationship_typeto group rows into different nodes and edges creates a much more useful and insightful data model to traverse. You can think about this projection as "exploding" the abstract relational model into more concrete objects.
Relational data models are typically not as vague or abstract. Additionally, data access patterns useful in a graph database might not have been considered when designing the relational schema.
Design hybrid data architecture¶
Innovation doesn’t necessarily require the latest/greatest technology. Graphs might be new (and appealing) too many developers, but it’s almost always better to balance the use of one with a more familiar relational database. Best practices target ETL of source data into a relational Data Lake first, then project into a graph database for purpose-specific traversals. Managing eventual consistency between data engines in a hybrid architecture helps identify data quality issues that might go unnoticed with one engine. Good data quality and observability is a must for designing hybrid data architecture.
Cosmos DB best practices¶
The following sections provide guidance on Cosmos DB graph implementations.
Cosmos DB ingestion¶
A simple method used to add data to Cosmos DB uses gremlin queries to add edges (g.AddE()) and vertices (g.AddV()) directly to the data store. Adding data this way does result in performance decrease because of validation checks. These checks confirm the existence of both the "in vertex" and the "out vertex" when creating edges.
Because of the multi-model nature of the Cosmos DB, this server-based validation can be bypassed by using the bulk executor in either the .NET or Java SDKs.
The developer creates the entities and relationships with standard development objects (POCO/POJO). Then GraphBulkExecutor translates the objects into correctly structured Cosmos DB documents and inserts them directly into the document database using the Cosmos DB SQL API. Because the documents and relationships are well formed in the code, there's no need for background validation of the related vertices. This approach can yield a performance improvement of up to 100X for loading large datasets.
To support migration paths from the various sources to the different Azure Cosmos DB APIs, there are multiple solutions that provide specialized handling for each migration path.
Partitioning a Cosmos DB¶
One common anti-pattern for Cosmos DB is misalignment between partitioning and traversal data access patterns. Designing a large graph data model without effective partitioning leads to expensive and long-running queries. This graph-partitioning guide explains how to partition a graph in Cosmos DB. The best practices listed are:
- Always specify the partition key value when querying a vertex.
- Use the outgoing direction when querying edges whenever it's possible.
- Choose a partition key that will evenly distribute data across partitions.
- Optimize queries to obtain data within the boundaries of a partition.
Apache TinkerPop Gremlin query steps allow for traversals across in, out, and both directions. In Cosmos DB, outgoing edges are stored with their source vertex. The following diagram (from the Cosmos DB graph partitioning documentation), uses color to show this optimization. 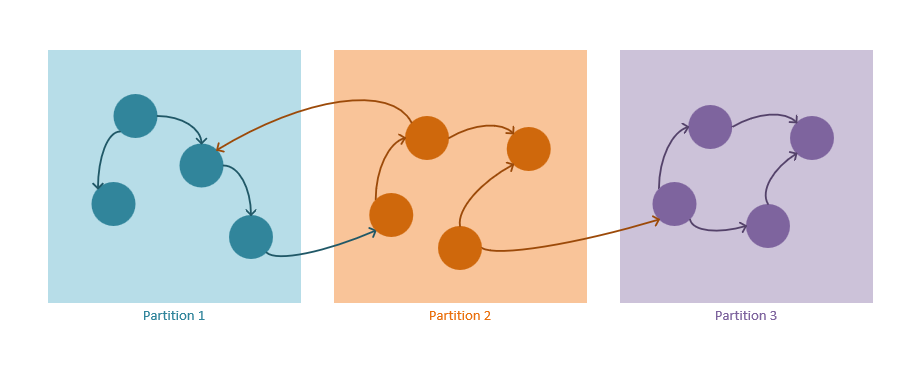
Optimize Cosmos DB with bi-directional edges¶
In Cosmos DB, outgoing vertex edges are stored in the same partition. A query for connected vertices that go out from a vertex only needs to search one partition. However, a query to find vertices with incoming edges to a vertex has to search all vertices in the database that have an outgoing vertex to the base vertex.
Consider this example of a Cosmos DB graph populated with data from a blogging site like Medium. Users are represented by either Reader or Author vertices and interact with Article vertices. Readers follow Authors and Readers also like Articles that Authors write. This data model might commonly have data access patterns that begin with traversals starting at Reader A and hopping along the follows edge. Given some sensible reader_id partitioning strategy, this traversal benefits from the outgoing edges to Authors vertices being stored on the Reader vertex.
However, answering questions about an Author's readership will suffer if using .in() steps from the Author vertex to the Reader vertices, which are stored outside of the partition. To improve the performance of .in() step queries, the data model flips the follows edge and stores an is_followed_by edge in the opposite direction. With this approach, a query of "the followers of any given author" or "the authors followed by any given reader" will benefit from having a "bidirectional edge" stored in the vertex partition. Keep in mind, this model comes at the cost of maintaining twice the edges.
Storage is cheap, and the compute reduction from bidirectional edges should outweigh any cost of doubling the number of edges stored. Data modeling a graph should consider traversal access patterns when deciding which edges to doubly store.