Implement CI/CD for Azure Databricks data pipelines¶
Problem Statement: By using the Medallion architecture, data pipelines can be created using Azure Databricks to build a reliable and trustworthy central hub for enterprise data. In order to maintain such a system in production, it's important to test and safely deploy the underlying code.
This article explains how to implement a CI/CD approach to develop and deploy data pipelines on Azure Databricks using Azure Pipelines.
Understand the architecture¶
Here is the high-level architecture diagram of the solution:

Use Databricks workspaces¶
The data pipelines run on Azure Databricks. It is best practice to have separate Databricks workspaces for development and testing (integration), staging, and production environments.
Set up source control¶
A source code repository is needed to store the data pipelines. The example uses Azure Repos, but other Git providers can be used as well. Databricks repos provide a repository-level integration with Git providers. This integration allows developers to develop and test code as notebooks and sync it with a remote Git repository.
Set up the CI pipeline¶
The CI pipeline includes two stages: running unit tests and then publishing artifacts for CD pipelines.
Set up the CD pipeline¶
The CD pipeline includes three stages:
- Deploy data pipelines as Databricks jobs to staging environment.
- Run integration tests over the deployed data pipelines in the staging environment.
- If integration tests pass, deploy data pipelines to production environment.
CI/CD is a general methodology, and can be implemented in different ways. Below are different implementations for some of DevOps CI/CD stages depending on whether the pipelines use Python modules/wheels or pure notebooks.
| Pipeline | Stage | Python modules/wheels solution | Notebooks solution |
|---|---|---|---|
| CI | Run unit tests | Use Pytest to do unit tests | Use Nutter to do notebook tests |
| CI | Publish artifacts | Publish built Python wheel files | Publish notebooks |
| CD | Deploy Databricks jobs | Install Python wheel to Databricks cluster before deploy Databricks jobs | Import notebooks to Databricks workspace before deploy Databricks jobs |
Overview of a sample CI/CD Pipeline¶
Let's take Python notebooks solution and Azure CI/CD pipelines as an example to elaborate more details on the whole end-to-end DevOps solution. Below are required key steps.
- Develop and test data pipeline notebooks in Dev Databricks workspace. If following the Medallion Architecture, create three notebooks for data ingestion, transformation, and curation respectively. Create relevant notebook tests using Nutter framework.
-
Add a Git repo and commit relevant data pipeline and test notebooks to a feature branch.
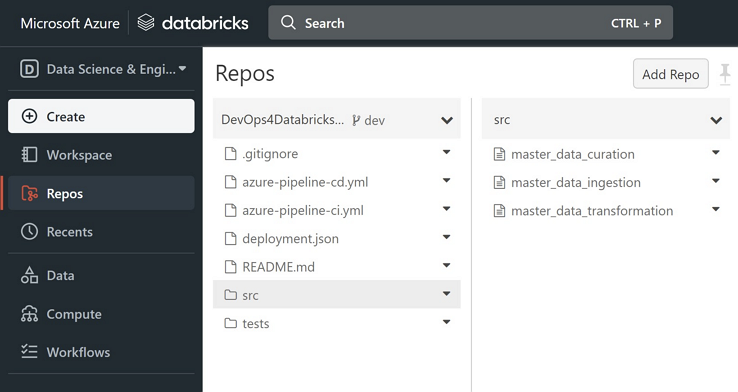
-
"Checkout" the Git repo in local IDE and add YAML files for Azure CI/CD pipelines.
-
The CI pipeline runs unit tests (via triggering notebooks), then publishes the notebooks as artifacts.
- This example uses Nutter CLI to trigger notebook Nutter tests.
- If notebook tests pass, then in publishing artifact stage, all notebooks will be packed as an Azure artifact that will be used in CD pipeline.
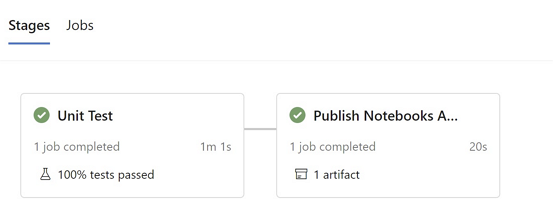
Following are relevant pipeline stages yaml configurations: - It uses databricks CLI to import source notebooks to user account's Databricks workspace, so that tests triggered by different developers with different commits won't affect each other. - It uses Nutter CLI to run the unit tests.
For more details on how to write Nutter tests, see the Nutter notebook test framework and modern-data-warehouse-dataops/single_tech_samples/databricks documentation and examples.
stages: - stage: UT displayName: Unit Test variables: - group: dbx-data-pipeline-ci-cd jobs: - job: NotebooksUT pool: vmImage: ubuntu-latest displayName: Notebooks Unit Test steps: - task: UsePythonVersion@0 inputs: versionSpec: '$(pythonVersion)' - script: | python -m pip install --upgrade pip pip install databricks-cli pip install nutter displayName: 'Install databricks and nutter CLI' - script: | databricks workspace import_dir --overwrite . /Users/$(Build.RequestedForEmail)/$(Build.Repository.Name)/$(Build.SourceVersion)/ displayName: Import unit test notebook to Databricks workspace env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - script: | databricks libraries install --cluster-id $CLUSTER --pypi-package nutter displayName: 'Install nutter library on Databricks Cluster' env: CLUSTER: $(DATABRICKS_CLUSTER) DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - script: | nutter run //Users/$(Build.RequestedForEmail)/$(Build.Repository.Name)/$(Build.SourceVersion)/tests/ $CLUSTER --recursive --timeout 600 --junit_report displayName: 'Run nutter unit tests' env: CLUSTER: $(DATABRICKS_CLUSTER) DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - task: PublishTestResults@2 inputs: testResultsFormat: 'JUnit' testResultsFiles: '**/test-*.xml' testRunTitle: 'Publish test results' condition: succeededOrFailed() - stage: PublishArtifact condition: succeeded('UT') displayName: Publish Notebooks Artifact jobs: - job: PublishingNotebooks displayName: Publish artifacts steps: - task: PublishPipelineArtifact@1 displayName: Publish artifacts inputs: targetPath: '$(Pipeline.Workspace)' artifact: 'DBXDataPipelinesArtifact' publishLocation: 'pipeline'
-
The CD pipeline includes the following stages:
-
Deploy the entire data pipeline as a Databricks job to the staging environment using the Databricks CLI and dbx (Databricks CLI eXtensions) CLI, while utilizing the dbx deployment.json format.
# Import source notebooks from Azure artifact to target Databricks workspace databricks workspace import_dir --overwrite "{source_notebooks_path}" "{target_notebooks_path}" # Export environment variable DATABRICKS_HOST and DATABRICKS_TOKEN before running below command to configure the project environment dbx configure # Define Databricks job in deployment.json file to chain those three data pipeline stages, then 'dbx deploy' would help to create defined Databricks job # in target Databricks workspace; or use --assets-only options to only upload job definition to Databricks but not create actual job in workflows/jobs UI dbx deploy --deployment-file=deployment.json --assets-only --tags commit_id=$commit_id --no-rebuild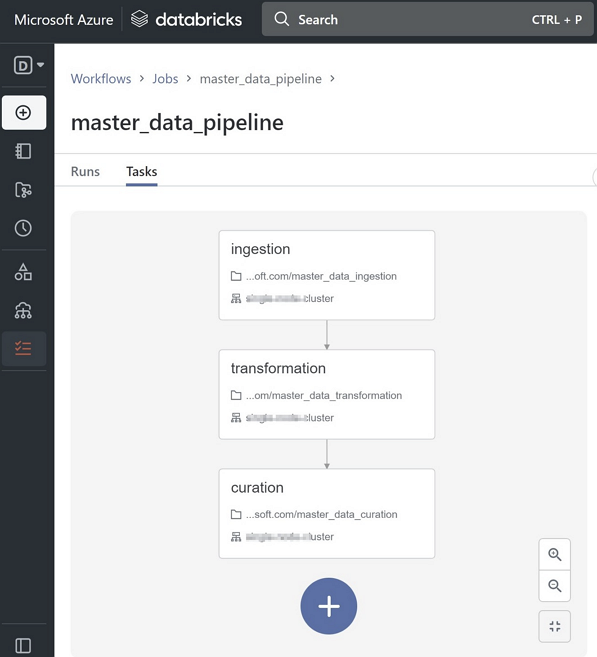
-
Run integration tests on the staging Databricks workspace.
-
Trigger the data pipeline job by 'dbx launch'.
- Run an integration test notebook to fetch the curated data results and do some assertion. - If the integration test passes, perform the same steps as in the first stage but this time deploy the data pipeline to the Production environment.
-
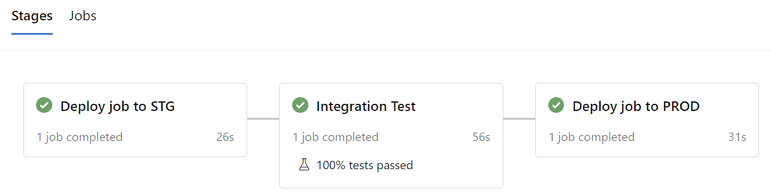
Below are yaml configurations for relevant CD pipeline stages: - Deploy job to STG - In this stage, source notebooks are imported to user account's workspace to segregate different pipeline runs triggered by different developers and commits. - Before deploying data pipelines, paths of referenced notebooks are updated in deployment.json file to link the right notebooks imported in the previous task. - The pipeline uses
--assets-onlyand--tagsoptions when deploying data pipelines to Databricks. With the--assets-onlyoption, workflow definition, relevant referenced files, and core packages will be uploaded to Databricks default artifacts storage, but actual data pipelines won't be created or updated in workflows/jobs UI. Identifier tags like a commit ID allow avoiding potential conflicts from different pipeline tests. For more information, see dbx deploy reference. - Integration Tests - In this stage, the pipeline uses--from-assetsand--tagsoptions to locate the correct data pipeline artifacts to test. It then triggers a one-time run using thedbx launchcommand. For more information, see: dbx launch reference. - Deploy job to PROD - In this stage, the--assets-onlyoption is not specified fordbx deploycommand to create/update data pipelines in workflows/jobs UI.This sample uses the dbx CLI to deploy and launch data pipelines/workflows. An alternate option is utilizing the Databricks REST Jobs APIs which need to include logic such as running a data pipeline by REST job API, waiting for its completion, and validating the test results in a single test script. This test can be run as a single task in the integration test stage.
stages: - stage: DeployDatabricksJob2STG displayName: Deploy job to STG variables: - group: dbx-data-pipeline-ci-cd jobs: - deployment: DeployDatabricksJob2STG displayName: Deploy workflow/job to STG environment: 'STG' strategy: runOnce: deploy: steps: - task: UsePythonVersion@0 inputs: versionSpec: '$(pythonVersion)' - script: | python -m pip install --upgrade pip pip install databricks-cli pip install dbx displayName: 'Install Databricks and dbx CLI' - script: | cd $(Pipeline.Workspace)/ci_artifacts/DBXDataPipelinesArtifact/s databricks workspace import_dir --overwrite . $WORKSPACE_DIR env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) WORKSPACE_DIR: /Users/$(Build.RequestedForEmail)/$(Build.Repository.Name)/$(Build.SourceVersion) displayName: 'Import notebooks to STG Databricks' - script: | cd $(Pipeline.Workspace)/ci_artifacts/DBXDataPipelinesArtifact/s sed -i "s|{workspace_dir}|$WORKSPACE_DIR|g" deployment.json dbx configure dbx deploy --deployment-file=deployment.json --assets-only --tags commid_id=$(Build.SourceVersion) --no-rebuild displayName: 'Deploy Databricks workflow/job by dbx' env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) WORKSPACE_DIR: /Users/$(Build.RequestedForEmail)/$(Build.Repository.Name)/$(Build.SourceVersion) - stage: IT condition: succeeded('DeployDatabricksJob2STG') displayName: Integration Test variables: - group: dbx-data-pipeline-ci-cd jobs: - job: NotebooksIT pool: vmImage: ubuntu-latest displayName: Notebooks Integration Test steps: - task: UsePythonVersion@0 inputs: versionSpec: '$(pythonVersion)' - script: | python -m pip install --upgrade pip pip install databricks-cli pip install dbx pip install nutter displayName: 'Install databricks, dbx and nutter CLI' - script: | databricks libraries install --cluster-id $CLUSTER --pypi-package nutter displayName: 'Install Nutter Library on Databricks cluster' env: CLUSTER: $(DATABRICKS_CLUSTER) DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - script: | dbx configure dbx launch master_data_pipelines_by_dbx --from-assets --tags commid_id=$(Build.SourceVersion) --trace --existing-runs wait displayName: 'Run deployed Databricks data pipeline/workflow' env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - script: | nutter run /Users/$(Build.RequestedForEmail)/$(Build.Repository.Name)/$(Build.SourceVersion)/integration_tests/ $CLUSTER --recursive --timeout 600 --junit_report displayName: 'Run integration tests' env: CLUSTER: $(DATABRICKS_CLUSTER) DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) - task: PublishTestResults@2 inputs: testResultsFormat: 'JUnit' testResultsFiles: '**/test-*.xml' testRunTitle: 'Publish test results' condition: succeededOrFailed() - stage: DeployDatabricksJob2PROD condition: succeeded('IT') displayName: Deploy job to PROD variables: - group: dbx-data-pipeline-ci-cd jobs: - deployment: DeployDatabricksJob2PROD displayName: Deploy workflow/job to PROD environment: 'PROD' strategy: runOnce: deploy: steps: - task: UsePythonVersion@0 inputs: versionSpec: '$(pythonVersion)' - script: | python -m pip install --upgrade pip pip install databricks-cli pip install dbx displayName: 'Install Databricks and dbx CLI' - script: | cd $(Pipeline.Workspace)/ci_artifacts/DBXDataPipelinesArtifact/s databricks workspace import_dir --overwrite src $WORKSPACE_DIR/src env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) WORKSPACE_DIR: $(PROD_WORKSPACE_DIR) displayName: 'Import notebooks to PROD Databricks' - script: | cd $(Pipeline.Workspace)/ci_artifacts/DBXDataPipelinesArtifact/s sed -i "s|{workspace_dir}|$WORKSPACE_DIR|g" deployment.json dbx configure dbx deploy --deployment-file=deployment.json --no-rebuild displayName: 'Deploy Databricks workflow/job by dbx' env: DATABRICKS_HOST: $(DATABRICKS_HOST) DATABRICKS_TOKEN: $(DATABRICKS_TOKEN) WORKSPACE_DIR: $(PROD_WORKSPACE_DIR) -
-
Using the above CI/CD pipelines with unit and integration tests allows changes to data pipelines to be safely and efficiently deployed across environments.
For more example implementations of CI/CD on Azure Databricks, see Azure Databricks: Use CI/CD.
For a concrete code implementation of CI/CD on Azure Databricks, see MDW Data Repo: Azure Databricks CI/CD