How to set up config driven data pipelines¶
This article describes the process to set up an extensible and configurable data platform consisting of multiple data pipelines. These pipelines ingest, transform, and curate data from multiple source systems and producers. Data can be in different formats with varying business logic to be applied during the transformation and curation of datasets. Building and maintaining individual data pipelines by hand is not feasible in the long term. For example:
- A food manufacturing company that wants to ingest food recipes from the on-premises servers of its multiple factories and provide a curated view.
- A solution provider that wants to build a configurable and reusable common data platform. Such a platform should reduce development efforts during ingestion, transformation, and curation from different data sources and, in turn, reduce time to insights.
A config driven data platform should:
- Enable designing data pipelines that are able to be converted into databricks jobs at run-time using configuration files.
- Provide a low-code/no-code data app solution for the customer's business or operation teams.
Solution overview¶
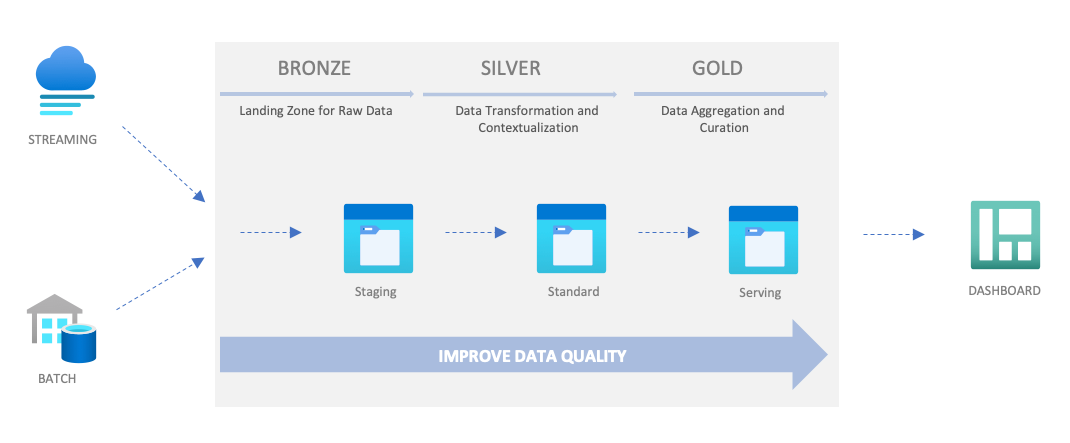
This solution is following the Medallion Architecture introduced by Databricks. The previous diagram shows a data pipeline that includes three layers/zones: Bronze, Silver, and Gold. In data platform projects, these zones are also called Staging, Standard and Serving. A data pipeline handles the flow of data from an initial source to a designated endpoint. Usually, a data system consists of multiple data pipelines for different types of batch/streaming data.
| Zone | Description |
|---|---|
| Bronze/Staging | The ingested data from external systems is stored in the staging zone. The data structures in this zone correspond to the source system's table structures "as-is". This structure also includes any metadata columns that capture the load date-time, process ID, etc. |
| Silver/Standard | The cleansed data from the staging zone is transformed and then stored in the standard zone. It provides enriched datasets for further business analysis. The master data could be versioned with slowly changed dimension (SCD) patterns and the transaction data deduplicated and contextualized with master data. |
| Gold/Serving | The data from the standard zone is aggregated and then stored in the serving zone. The data is organized in consumption-ready "project-specific" databases, such as Azure SQL. |
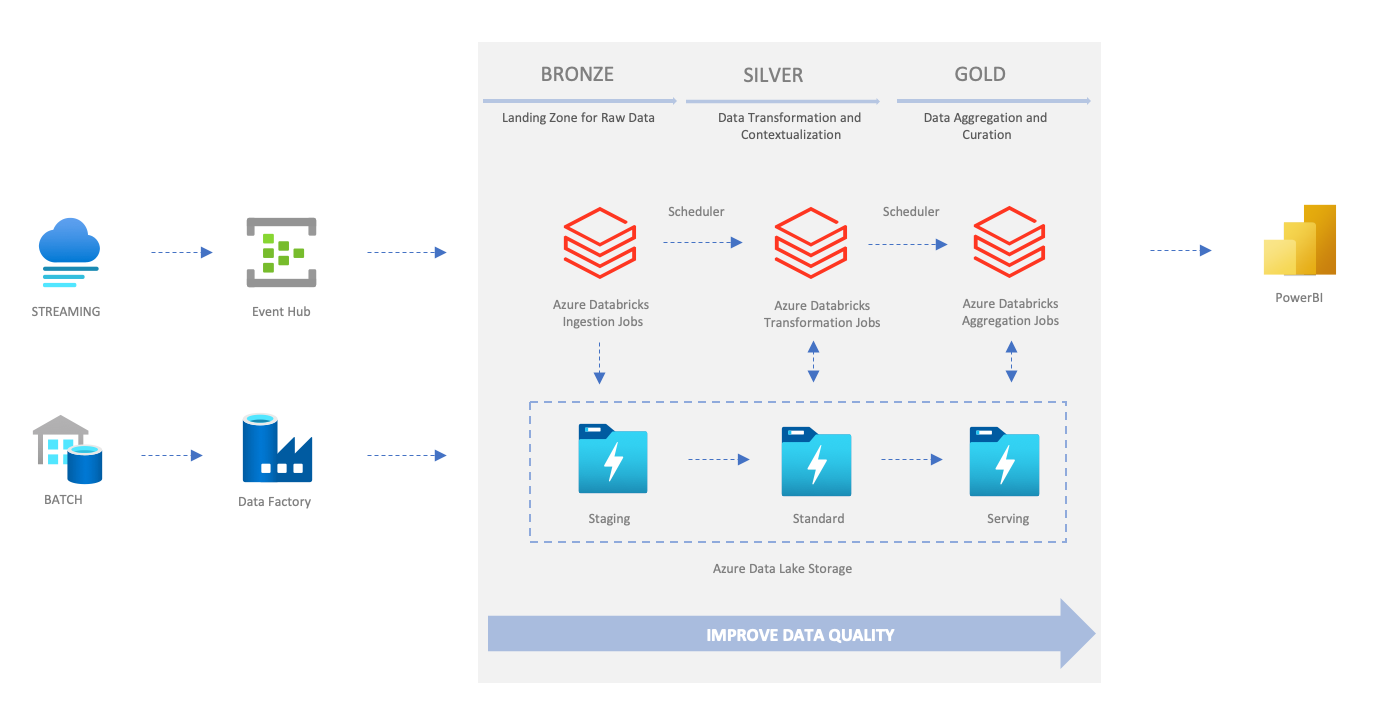 The preceding picture shows a typical way to implement a data platform consisting of multiple data pipelines based on Databricks.
The preceding picture shows a typical way to implement a data platform consisting of multiple data pipelines based on Databricks.
- Azure Data Factory loads external data and stores it in Azure Data Lake Storage.
- Azure Data Lake Storage (ADLS) functions as the storage layer of the staging, standard, and serving zone.
- Azure Databricks is the calculation engine for data transformation, and most of the transformation logic implements with PySpark or SparkSQL.
- Azure Synapse Analytics or Azure Data Explorer is the solution of serving zone.
The medallion architecture and Azure big data services provide the infrastructure for an enterprise data platform. Then, data engineers build transformation and aggregation logic with programming languages such as Scala, Python, SQL, etc. Furthermore, applying DevOps principles such as CI/CD and monitoring is crucial for efficiently operationalizing the solution.
To make the solution extensible and configurable, design the system using a configuration that consists of entities, attributes, relationships, rules, etc. Within this system, build the data pipelines based on a framework and the configuration (metadata) defined by the users.
A sample architecture for configurable framework¶
The following diagram shows the architecture of an end-to-end sample solution that illustrates a configurable and reusable framework to build data pipelines.
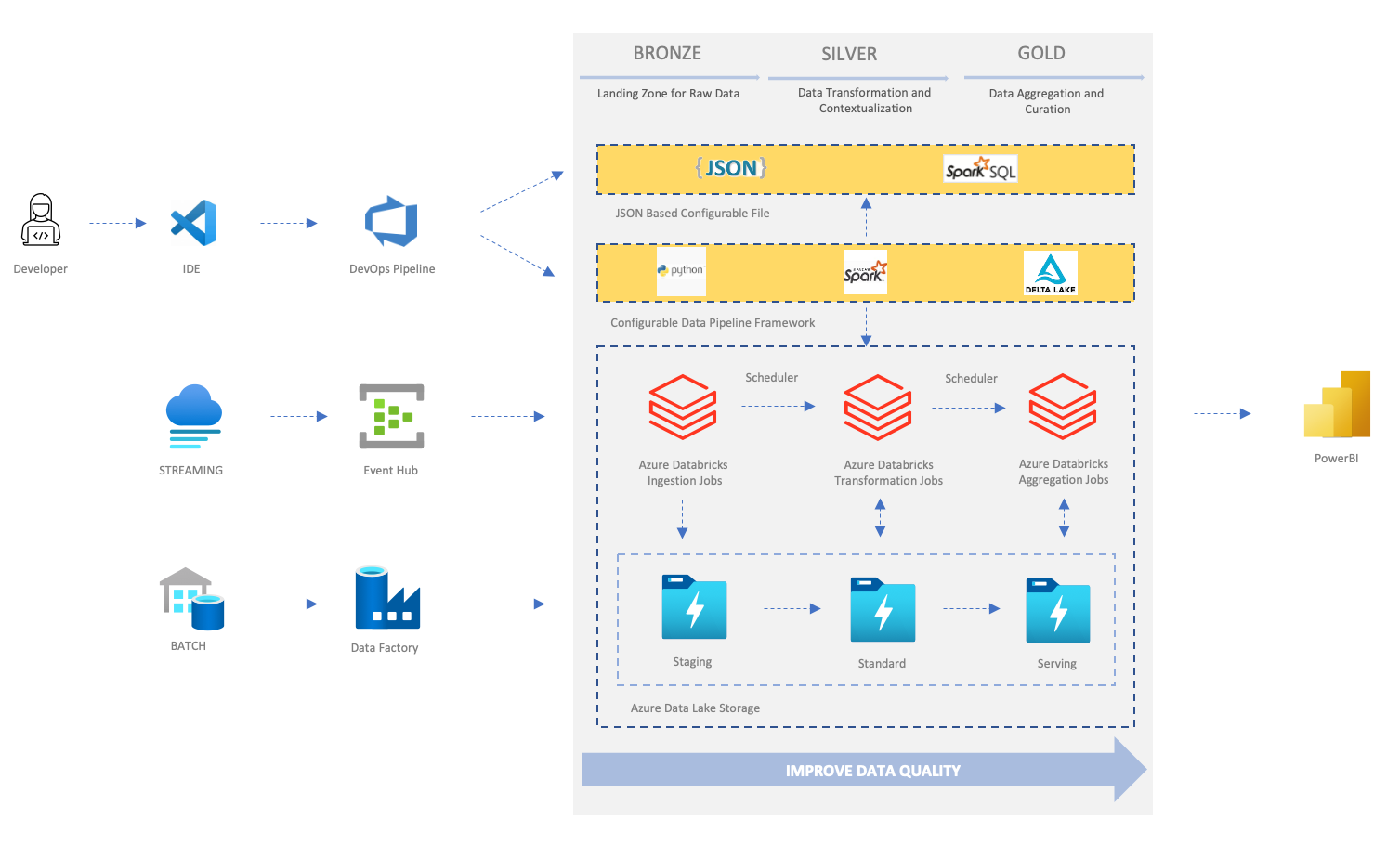
The sample solution processes two kinds of data:
- Master data
- Data about the business entities that provide context for business transactions
- Data processing type: batch processing
- Event/transactional data
- Transactions captured data used in reporting and analytics
- Data processing type: stream processing
Both master and event data go through staging, standard and serving zones. Then, finally, the dataset is ready for downstream and business consumption.
The solution includes two parts:
-
Framework: It loads the configuration files and converts them into Databricks Jobs. It encapsulates complex Spark clusters and job run-times and provides a simplified interface to users, who can focus on the business logic. The framework is based on PySpark and Delta Lake and managed by developers. The framework supports the following types of pipelines:
- Master data pipelines: batch processing for the master data.
- Event data pipelines: stream processing for the event data.
-
Configuration: The configuration or metadata file defines:
- The pipeline zones.
- Data source information.
- Transformation and aggregation logic implemented in SparkSQL.
Developers can add and update the configuration using IDEs and Azure Pipelines. In future versions, shown in the diagram below, the configuration can also be managed by a set of APIs. The technical operation team is able to manage the pipeline configuration via a Web UI on top of the API layer.
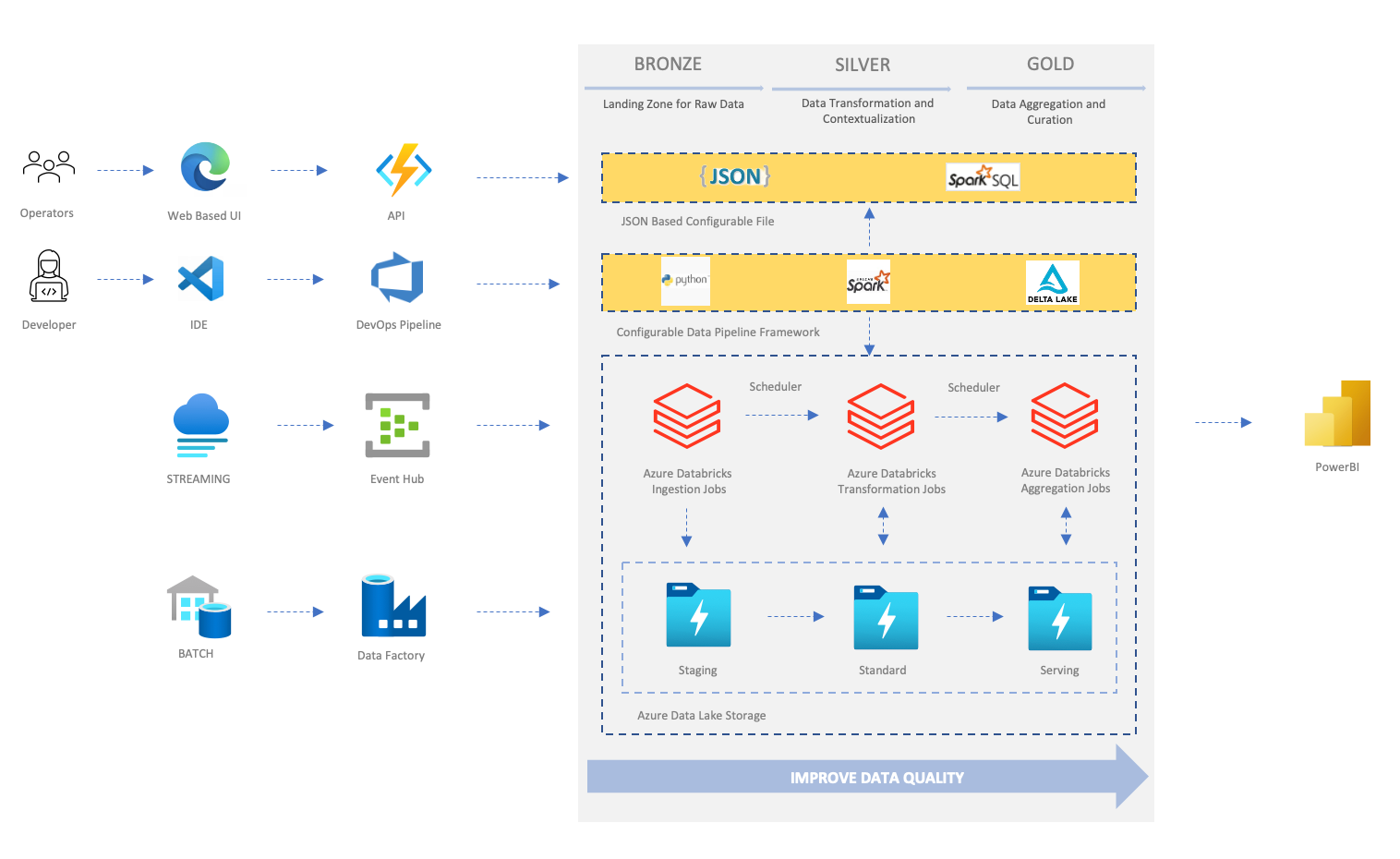
Setting up the technical stack¶
To set up a solution of config/metadata driven data pipelines, you need the following components in the technical stack. The following is a list of relevant Azure services.
| Component | Azure Service |
|---|---|
| Apache Spark | Azure Databricks |
| Data lake storage | Azure Data Lake Storage Gen 2 |
| Delta Lake | Delta Lake managed by Azure Databricks |
| A workflow system (Optional) | Azure Databricks jobs and tasks, Azure Data Factory |
| A data warehouse (Optional) | Azure Synapse Analytics |
| A data visualization tool (Optional) | Power BI |
Accessing the sample code¶
For more detailed instruction and the source code of the end-to-end sample solutions, refer to Config-driven Data Pipeline.